當KM遇見Big Data-以台灣IBM公司為例

- 撰文者:
- 2015/08/13 瀏覽數:8058

從「找人幫忙」到「找知識幫忙」-巨量資料(Big Data)的崛起
知識管理是企業一直以來重視的課題,其管理手法已逐漸從過去以專家為基礎的「找人幫忙」,到現在開始以資料為基礎的「找知識幫忙」,其中轉變的決定性因素,便是巨量資料(Big Data)運用的出現。Big Data運用的關鍵即是資料挖掘(Data mining),如何在龐大、繁瑣且看似無用的資料中發掘有用的資料,並經過分析與連結後排列組合成新的價值是最重要的核心問題(圖一 Big Data的應用)。

圖一 Big Data的應用
巨量資料(Big Data)的應用
巨量資料在實用層面的影響非常大,能夠為日常生活棘手的問題找到答案。而且,這還不過只是開端而已,巨量資料可能會徹底重塑我們的生活、工作和思考方式[1]。
巨量資料被譽為21世紀的新石油,目前已應用於各種領域,例如Google分析人們在搜尋引擎有關感冒症狀的關鍵字資料推測出何處即將爆發流行性感冒、企業利用路口監視資料推測行人流量可以帶來多少商機、地圖公司從眾多的圖資照片中分析及篩選出兩地之間的路線方式供消費者選擇、流通業利用顧客的消費資料篩選出顧客的消費特性以進行精準且客製化的行銷。
除此之外,若巨量資料結合動態模擬能力,對於企業而言,可以盡早知道該在何處(員工年終、生產成本)調整以達到特定的營收或利潤;甚至在選舉操作面,筆者亦在碩士論文中嘗試利用選舉結果的得票資料模擬各政黨在不同選舉制度下的得票結果,並推論出小黨支持何種選舉制度對自己最有利。
更值得一提的是,當Open Data(政府開放資料)結合Big Data,亦能激發出創意的應用。麵包店業者從政府開放的氣象資料可以得知該地區的氣溫、晴雨等天候資料,結合比對顧客的消費偏好和麵包款式等交易資料後,進而發現顧客在何種氣候狀況下有特定的麵包偏好款式,使店家得以依據天氣預報資料預先烘焙相對應的麵包,這樣的精準行銷方式將有效減少滯銷與庫存。
以台灣IBM公司為例
- 「 Data-mining」(資料挖掘)到「Text-mining」(句構挖掘)
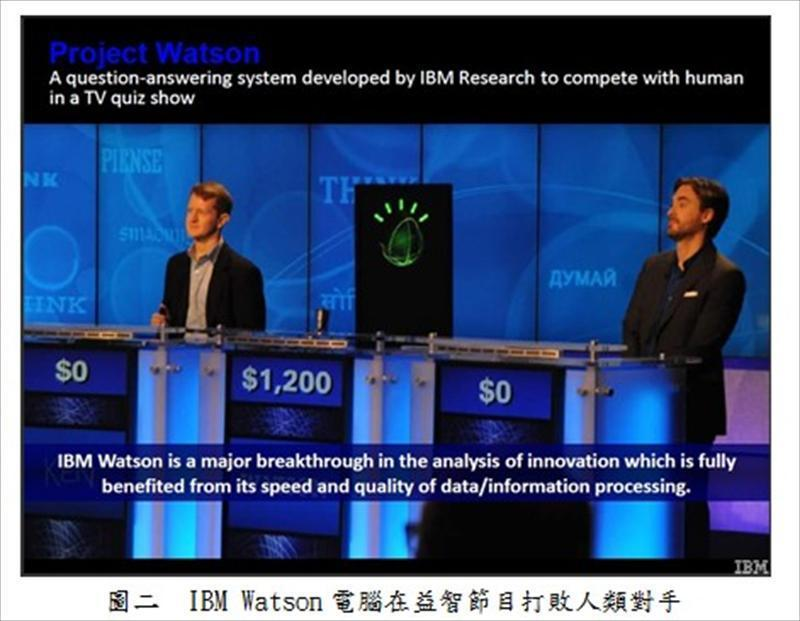
更靈活的運用方式如IBM公司,目前所開發出的智慧電腦Watson(華生),是一個以超強效能執行高度運算與深度分析的龐大巨量資料庫,已在美國益智節目(Jeopardy!)打敗人類對手(圖二[2])。
Watson除了理解程式語言之外,更能夠解讀自然語言的能力-換句話說,Watson能夠與人類對話-目前已逐步應用於醫療領域:在醫生看診時輔助分析病人所述症狀,並列出病人可能受感染的疾病,「輔助」(並非取代)醫生決策與判斷。
此外,IBM將與Facebook合作,協助針對使用者所貼的文章字句結構進行分類,例如將使用者的文字歸類為政治類、運動類、情感抒發類後推測使用者的興趣與近期需求,以利廣告商於使用者頁面出現的Banner能夠精準行銷,而非漫無目的地跳出不切中需求的廣告頁面,徒增使用者困擾。
可知,象徵 Big Data運用的手法也逐漸從「 Data-mining」(資料挖掘)到「Text-mining」(句構挖掘)。
- 當KM遇見Big Data-從管理走向協作
就IBM的發展進程而言,已從過去的「硬體服務(電腦)」逐漸轉型成「軟體服務(系統、資料)」。就軟體服務而言,最貼切的例子即是自五年前開始,台灣IBM公司內部開始以Big Data結合社群網站的概念運作知識管理系統。
事實上,更精確地說,IBM並不稱它為知識管理系統,而是知識協作系統(IBM Connection)。對於IBM而言,知識的分享比知識的管理更為重要,因為知識不應該只是靠管理者管理,而是要靠成員自發地分享,因此社群應用便是IBM的首選。
有關IBM Connection的社群應用特色,例如:
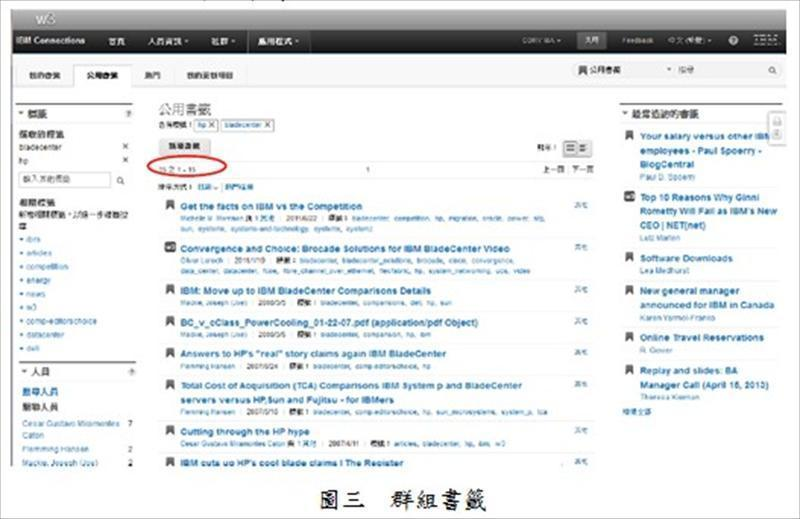
- 群組書籤(social bookmark)
個人在解決問題的過程中將有用的檔案和網站標記起來,在找尋答案的同時進行知識累積與分享,讓下一個需要解決類似問題的人「有跡可循」,可以直接在社群內部搜尋有用且可靠的知識,不用再花時間到搜尋引擎上重新過濾有用的資料,讓個人所收集到的外部知識真正成為企業資產(圖三 群組書籤[3])。
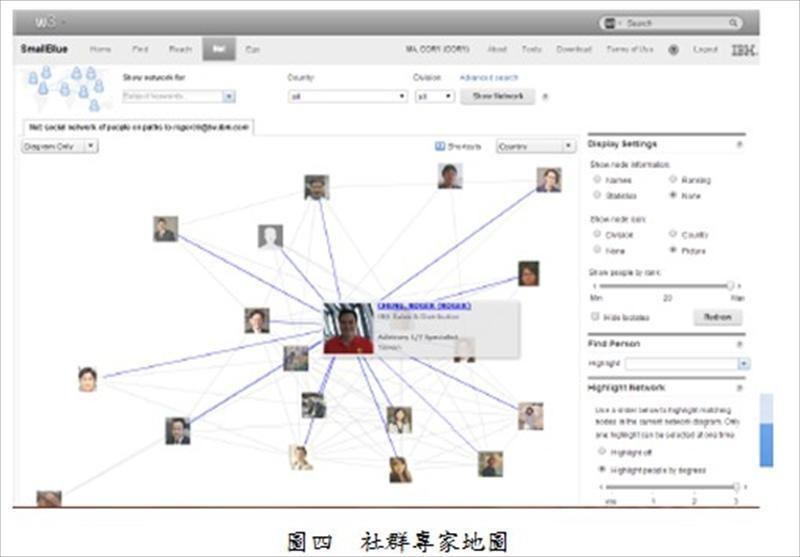
- 社群專家地圖(social network of people)
以「人」為知識核心,了解誰的網絡跟自己有關?誰的興趣和專長與自己相似?誰的專長能幫我解決問題?先透過網絡找對專家,再了解必須透過誰找到這位專家,最後透過專家進一步發現知識(圖四 社群專家地圖[4])。
- 知識社群(community places)
包含產業知識社群和專案社群。透過社群,可以分享檔案、相片、影片、新聞、交換意見、共同撰寫知識文件、尋求協助,最終的目標就是集合群組智慧來腦力激盪(圖五 知識社群[5])。
圖五 知識社群
- IBM Connection成功的因素
對於IBM而言,他們知識管理(或稱「協作」)成功的關鍵,是因為社群讓員工感到凝聚力,並讓員工對社群產生依賴性與黏著性。
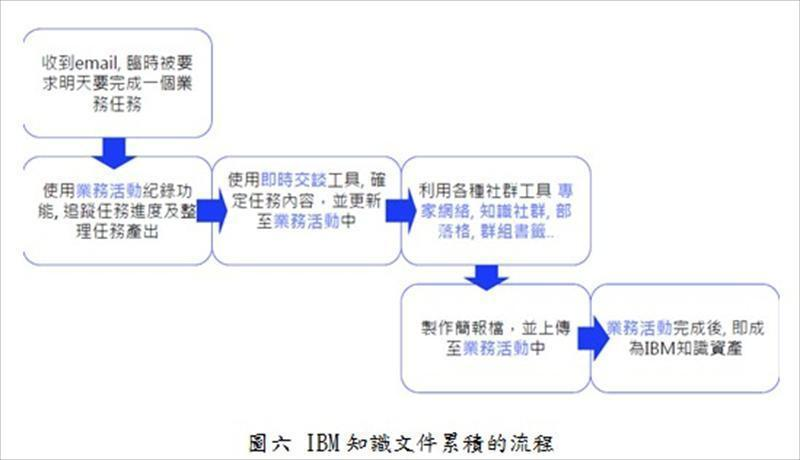
首先,由於IBM讓員工在解決問題時必須要與IBM Connection結合,因此員工在解決問題時即是在進行知識累積,並且讓知識分享及累積自然而然與業務流程結合,當單一員工完成任務時就等於是全公司受惠(圖六 IBM知識文件累積的流程[6])。
久而久之,當員工需要尋求解決方案時,不是拿起電話,也不是開啟Google,而是往IBM Connection這個龐大的資料庫中尋找知識文件,而且這些知識文件已經是同仁Data Mining過的資料,節省許多不必要的篩選時間。最終,建立以證據和資料為導向的決策方式、企業文化與管理模式[7] 。
再者,透過社群系統,員工得以快速累積自己的聲望(reputation),也就是社會資本。每當個人分享知識文件或在社群裡協助他人解決問題後,個人在他人心中會逐漸塑造某種領域的專家形象,此種由社會資本所帶來的象徵性權力,有助於個人在群體中建立聲望,進而使個人成為群體裡不可或缺的角色。
舉個有趣但實際的例子:即使個人不幸被同部門所裁撤或資遣,也因為個人在公司裡建立的社會資本,從而也可能被他部門邀請加入,產生「敗部復活」的效果。
- IBM經驗應用的反思
或許,企業主都了解,教員工使用資料,進而用資料解決問題,是為企業增添效益的最佳方法。但是成功經驗一定可以被複製嗎?
許多人心中都有相同的疑問:IBM的社群系統的確是很新穎也很有效,但是,每個企業都可以複製它們的成功經驗嗎?筆者以為,其實又回到知識管理是「先有分享文化再有管理系統」或是「先有管理系統再有分享文化」的討論。
就一般性的通念而言,大部分企業應該要先了解並建立內部的分享文化之後,再思考自己需要何種知識管理或分享的系統;相對地,就IBM公司而言,筆者以為則是先有社群系統,再透過它來建立(或著說是制約)企業內部的社群文化及員工個人行為。
不可諱言,IBM在先天上有著與其他企業不同的優勢,例如全球40萬員工所建立知識文件的速度,才能在短短的五年之內使社群系統成為一個強大的搜尋引擎,這種累積資料的能力絕對不是一般台灣中小企業可以相媲美的。
再者,延續前述企業規模的差異,大型公司或跨國企業的組織型態並非單一的科層組織,而是在不同的分公司會出現相同部門的複合體(例如台灣IBM分公司有行銷部門,美國IBM分公司也有行銷部門),當台灣分公司的行銷人員在工作過程中所遇到的困難,美國分公司行銷部門的同仁很有可能已經解決過類似的問題。
因此,問題很容易在社群系統上得到正面回饋而不是石沉大海。隨著使用者經驗的累積,當員工逐漸在龐大的社群分享系統累積成功解決問題的經驗後,便開始對系統產生信心,進而產生對系統的黏著性,這也可以合理解釋IBM Connection將資料從量化(龐大且雜亂的資料)到質化(有用的資料)的轉變過程中可以如此成功的原因。相對地,IBM這樣龐大的組織型態所帶來的成功,是占台灣企業規模70%的中小企業所望塵莫及的。
小結
巨量資料改變了我們的生活。這些改變,可能是最佳化、改善、更有效、或更有利。但我們必須知道,巨量資料不適一套冰冷的演算法和自動機器,一切還是必須和人密切相關[8] ,因為只有人,才能夠互相協作。
透過台灣IBM公司的經驗,除了驗證許多Big Data的應用之外,透過協作的概念,更突破對於知識管理系統的刻板認知,且IBM知識協作的推動方式,著實深刻驗證知識分享的真義-「得到社群協助的同時受惠的不只是個人」。
〔註〕
- 麥爾荀伯格、庫基耶著,林俊宏譯,2013,《大數據》,台北:遠見天下文化,頁265。
- 賈景光,2014,〈Big Data/Analytics未來趨勢與發展〉,台北:第四屆第2次知識長聯誼會,頁8。
- 馬西緯,2014,〈IBM知識協作推動實務分享〉,台北:第四屆第2次知識長聯誼會,頁33。
- 馬西緯,2014,〈IBM知識協作推動實務分享〉,台北:第四屆第2次知識長聯誼會,頁28。
- 馬西緯,2014,〈IBM知識協作推動實務分享〉,台北:第四屆第2次知識長聯誼會,頁41。
- 馬西緯,2014,〈IBM知識協作推動實務分享〉,台北:第四屆第2次知識長聯誼會,頁11。
- 湯瑪斯.戴文波特等著,許瑞宋等譯,2014,《哈佛教你精通大數據》,台北:哈佛商業評論,頁103。
- 麥爾荀伯格、庫基耶著,林俊宏譯,2013,《大數據》,台北:遠見天下文化,頁273。
猜你喜歡

「分類」是管理及研究的重要基礎,更是科學進步的重要關鍵,商業智慧(BI)已於全球發展了許多年,加上分析成為「商業智慧和分析」(BI&A),至少也有近20年的歷程,而國內似乎對「商業智慧和分析」並無明顯分類狀況,特別在大數據資料(Big Data Analysis)及行動裝置快速成長之時刻,未來企業資訊發展應如何跟進,或許正是許多經營者無法著墨的問題,故本文以「分類」為基礎,以期促成企業於資訊投資時的參考資料。

資料探勘確實是一門值得學習的技術,無論在各個領域的應用上,都能藉由紀錄的完整收集,呈現出資料的架構模式。

在新消費時代的顧客關係管理,除了新系統及新科技的運用外,另一重要成敗關鍵就是該如何有效的利用這些數據資料,提供我們作為問題發掘及決策參考之依據。大部份企業了解到顧客關係管理有其重要性及價值性,但就是沒發揮其顧客資料所帶來的價值,追溯其問題癥結,主要原因有二,一為對其相關資料不知該如何整理統計,二為不知該如何作分析解讀。因此可透過導入大數據運用思維來協助架構,筆者根據多年從事服務相關行業之輔導及實務經驗,提供一些規劃操作之執行步驟作為大家執行之參考。

Big Data、大數據亦或是巨量資料,儼然成為過去幾年來業界火紅的討論話題,相關的應用,像是顧客決策旅程規劃、多渠道行銷、智慧行動網路等等,對於「終端顧客」的衝擊都浮上檯面。但實際上仍有些漏網之魚,尤其是針對「農產品產業」,本文將以三個主軸:數據對農業未開發的潛力、大數據對於新興經濟中的農業衝擊以及對成熟經濟體的影響,來娓娓道出農業身為食物產業鏈的核心,如何使用大數據來重新翻轉。

因應物聯網時代的來臨,巨量數據衍生出資料庫革命,依據資料的重複使用頻率等特性,冷資料的數據,可即時利用作為當下超過設定臨界值,提供預警的功能,而某一固定間隔時段的統計數據,可提供做為大數據分析之用。但是一旦數據失去時效性,沒有發生異常示警或統計上的意義時,這些資料就可能同時失去了留存的價值。在新的NO SQL資料庫也無法滿足新的處理模式之下,時序資料庫勢必將取代傳統關聯式資料庫,作為目前巨量數據資料儲存的最佳可行方案。











跨世代溝通與領導-我和APP世代
上課時間 2026/08/11 ~ 2026/08/11
ESG永續碳會計管理實務 - ★線上視訊課程★ - 許文西老師
上課時間 2026/11/09 ~ 2026/11/10
KC2價值概念與成本意識 - 【關鍵就業力】
上課時間 2026/09/04 ~ 2026/09/04
讓數字說話:掌握企業會計與財務解析黃金法則 - LINE@ID:@274aywrg - 實體+遠距同步 - 張淵智老師
上課時間 2026/10/01 ~ 2026/10/01
EQ服務力:用情緒管理打造高效門市團隊
上課時間 2026/11/13 ~ 2026/11/13
生成式圖像及簡報應用 - 遠距教學
上課時間 2026/08/27 ~ 2026/08/27
如何參與政府採購與標案爭議處理 - 已達開班人數
上課時間 2026/08/19 ~ 2026/08/19
採購議價策略與談判研習班
上課時間 2026/08/26 ~ 2026/08/26
防火管理人訓練複訓班 - (高雄班)
上課時間 2026/12/15 ~ 2026/12/15
AIGC 賦能職場工作術 - 使用ChatGPT提升Excel資料處理與分析能力 - 建議可自備筆電 - 王仲麒老師
上課時間 2026/11/06 ~ 2026/11/06